
Infokurs: Schulhomepage (Nutzungsrechte)
Dieser Kurs vermittelt Schulen, wie Urheberrechtsverletzungen auf der Schulhomepage vermieden werden können. Lehrkräfte und Schulverantwortliche lernen:
- welche Inhalte bedenkenlos genutzt werden dürfen,
- welche Voraussetzungen erfüllt sein müssen, um urheberrechtlich geschützte Inhalte zu verwenden,
- wie Creative-Commons-Lizenzen korrekt angewendet werden und
- welche Werke durch das Zitatrecht eingebunden werden können.
Darüber hinaus erfahren die Teilnehmenden, wie alternative Inhalte zu geschützten Werken gefunden und genutzt werden können. Ein weiterer Schwerpunkt liegt darauf, Schulen dabei zu unterstützen, potenziell urheberrechtlich problematische Inhalte auf ihrer Homepage zu erkennen und zu prüfen. Das Ziel des Kurses ist es, die Grundlagen des Urheberrechts verständlich zu vermitteln, damit Schulhomepages frei von rechtlichen Risiken bleiben.
Falls Sie Fragen oder Beratungsbedarf haben, wenden Sie sich an die Ansprechpartner.
2. Mögliche Urheberrechtsverstöße finden
2.1. Wie funktionieren Suchmaschinen?
Um nachvollziehen zu können, wie Rechteinhaber ihre Werke auf anderen Websites wie etwa Schulhomepages finden können, ist es hilfreich zu verstehen, wie Suchmaschinen funktionieren.
Suchmaschinen indizieren alle Inhalte einer Website, die in irgendeiner Form über Links innerhalb der Website zugänglich sind, auch wenn es sich um einzelne schon viele Jahre alte Seiten oder News Beiträge handelt. Sie können Texte und auch PDF Dateien auslesen, um sie zu indizieren. Genauso können sie die Namen von Dateien auslesen. Die Indizierung erfolgt, indem spezielle Programme, sogenannte Crawler, alle Links, welche von öffentlichen Websites ausgehen, verfolgen. Dabei werden sowohl Links zu internen wie auch externen Inhalten verfolgt. Alle Dateien bis zu den grafischen Elementen, aus denen die einzelne Website besteht, werden dabei erfasst. Mediendateien können dabei je nach Format ebenfalls ausgelesen werden. Die Algorithmen einer Suchmaschine können so in Abhängigkeit von der Bildqualität auch Bildinhalte erkennen und sogar Text aus Bildern auslesen.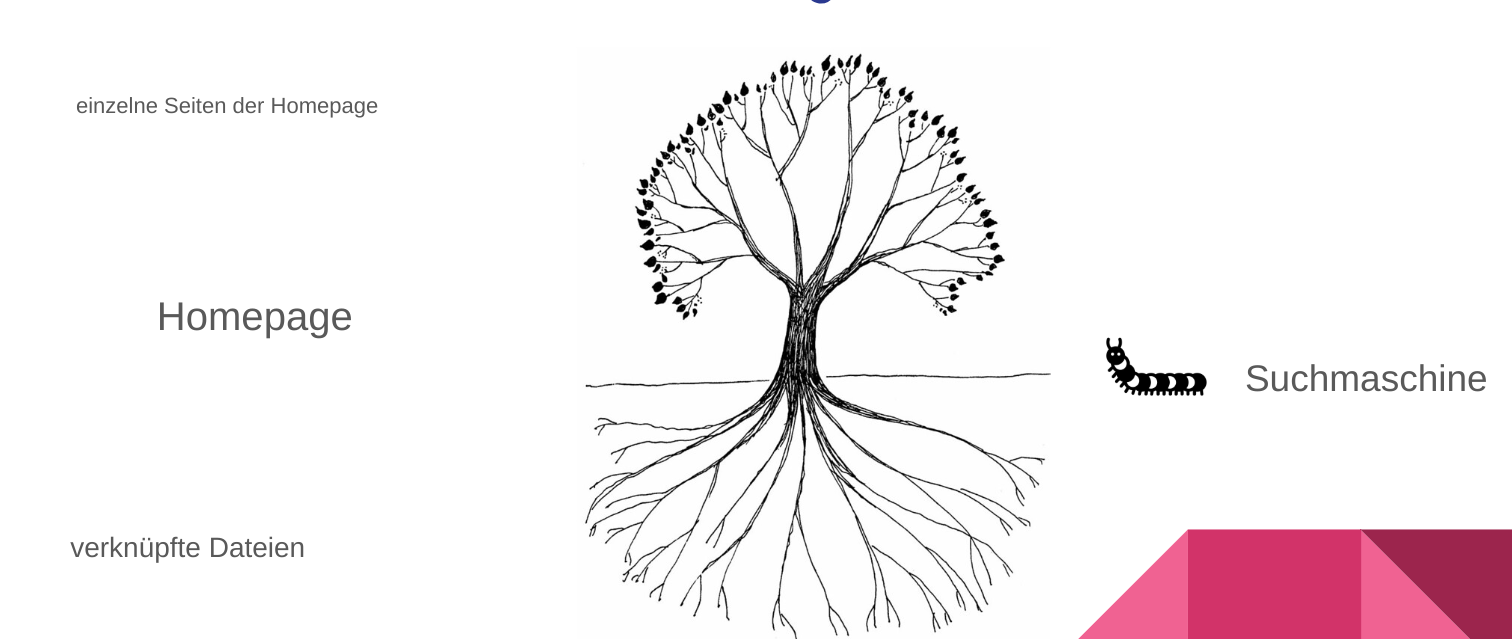
Der Index einer Suchmaschine, in welchem alle von den Crawlern erfassten Inhalte gespeichert werden, speichert diese erfassten Inhalte über längere Zeiträume, so dass manche Inhalte bei Suchen noch angezeigt werden, wenn sie bereits einige Zeit von der Website gelöscht wurden. Liegt eine Mediendatei, die einst in eine Seite der Schulhomepage eingebunden wurde, weiterhin im Medienspeicher, so ist die Wahrscheinlichkeit groß, dass Suchmaschinen den direkten Link zu dieser Datei weiterhin in ihrem Index hinterlegt haben. Damit ist die Datei auch weiterhin über die Suchmaschine auffindbar und erscheint entsprechend in Suchergebnissen.
Die Funktionen von Suchmaschinen kann man sich als Rechteinhaber zu Nutze machen, wenn man Urheberrechtsverletzungen ausfindig machen möchte.
Bildquelle: Jim Forest - tree with roots - CC BY NC ND 2.0; WEBTECHOPS LLP - caterpillar - Noun Project CC BY 3.0